Our regular contributor David Stickland of Global Dressage Analytics weighs in on this week's major debate on the improvement of the popularity of the dressage sport via an improved judging system.
The discussion started originally with Eurodressage's editorial Love's Labour's Lost after some staggering rule changes were announced at the FEI General Assembly in December 2014. Last week, Eurodressage published a related column by Michael Klimke, which prompted reactions from judges Stephen Clarke, Angelika Fromming, the FEI Dressage Committee, the IDRC and more. Read David Stickland's valuable input into the discussion:
David Stickland: Moving Towards a Stable Score Future
This week has seen an explosion of very interesting commentary around the Dressage Stakeholders meeting that took place on Wednesday. Thursday was Michael Klimke and Saturday saw Stephen Clarke enter the fray with his column here on Eurodressage.
If all the judges were as good as Stephen perhaps we would not be having this discussion so often but the reality is that even in our biggest most important events there are frequently large differences that have nothing to do with judging angle or position. They don’t necessarily have to do with good and bad judging either, but with a lack of precision in the judging system. It takes just a 0.5 point difference per figure to end up with a score difference of 5%, and that is how the big score differences arise, they have nothing to so with the judging position. (When we only had whole points the difference could easily become 10%!) Certainly the judge at C will see different things on the centerline to the judges at E and B for some figures, but those few figures do not lead to 5% differences. Indeed integrated over the whole test many of these effects average out also. No viewing angle can explain the large differences sometimes observed between B and E! At major events we have anomalies such as that of Micheal Eilberg in Herning and such anomalies will one day change medal positions. (6 judges averaging 73.39, one at 65.53)
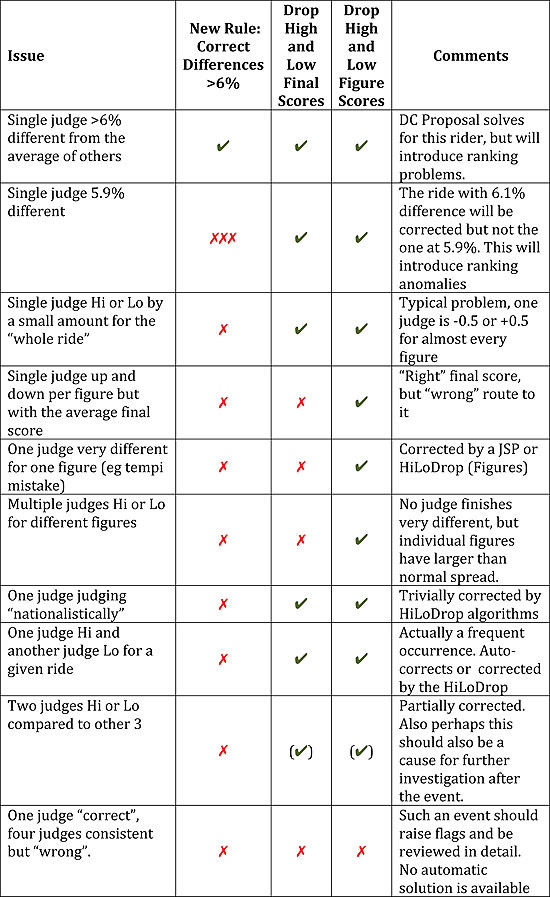
The Dressage Committee itself has proposed and has had passed by the General Assembly a new rule for 2015 that would allow a JSP to correct score differences greater than 6% (even after they have corrected individual figures!). So they recognize the problem, but their solution is dangerous. The difference of 6.1% will be corrected but not that of 5.9%? One day this will change the ranking of a medal and there will be uproar. They prescribed that the decision to correct a score must be unanimous in the JSP – sounds great, but it means that each JSP member can prevent or permit the correction. In fact any correction algorithm that has a threshold for its action, will inevitably introduce ranking anomalies.
HiLo Drop, Sensible Band-Aid to Improve the Judging System
Since the DC has recognized the problem, I feel justified in proposing a much simpler and more transparent algorithm that can be applied whenever there are 5 or more judge – figure by figure drop the highest and lowest note from the final score – I call it HiLoDrop (see figure below). As you see in the table it automatically addresses a large range of issues. I compare it with the new 6% rule and with the HiLoDrop(Final) variation where the highest and lowest judges final scores are dropped.
Stephen is absolutely right, statistically this makes only small changes compared to the current method, the spread in final score differences is only 0.15% (technical term: Standard Deviation) - compare this with the average single judge spread compared to their colleagues of 1.5-2% that means a final score only ever has a precision of about 0.5-0.8%. It is tiny for the majority of rides. Stephen uses this as an argument against such a correction, but that is precisely what we want, we don’t want to radically change anything we just want to improve the stability of the result. None of this is based on my opinion but is the result of studying the numbers in many events. At Herning for example I compare the 21 different ways of choosing 5 judges from 7 and then applying HiLoDrop. But it corrects the Eilberg effect at Herning completely - and a similar smaller effect for Adelinde. Stephen’s assertion that it would reduce everything to 6.5 and would be the end of the 10 is just wrong. It would have no such effect, it can lift scores as much as it can depress them (10,10,10,10,9.5 would become “10”!). To be more precise, I have performed the analysis and it has no such effect when applied to real competitions! If all our judges would decide to give 6.5’s then I guess that would be a problem, but I sort of doubt that would happen. The goal is not to give all riders the same score, but in any individual event to get the result that most reflects the majority opinion and which is the least sensitive to any single judge affecting the ranking.
I use a term that I call Rank Stability, it is the average number of Rank Changes per participant that would be caused by taking out one judge at a time. I calculate this for Herning comparing the 7 judge score; the 7 judge with High and Low judge dropped per figure; and the 21 possible combinations of 5 judges out of the 7. The HiLoDrop algorithm has 3 times better Rank Stability than any other combination of 5 judges, 0.5 rank changes per participant compared to 1.5. Of course most of these rank changes are in the middle of the field, if we restrict ourselves to the top ten positions than HiloDrop is 4 times better than any other combination of 5 judges! (0.2 instead of 0.8 rank changes/participant).
With this method every judge’s score still stands, but in the final score given to the couple the larger differences are automatically smoothed out. The differences still stand and they can be discussed and analyzed, but the rider is neither penalized nor benefits from such effects, Nationalistic judging is for example essentially completely eliminated. Nationalistic judging exists, it is clearly demonstrable and that, Michael Klimke, is a reason we moved to 7 judges in major events. It can just be due to a preference of style but Dutch judges do judge Dutch riders higher and German riders lower – and the German judges do the exact opposite! Again, that’s not an opinion; it is based on studying many years of CDIO events and measuring those shifts. Of course nobody should take comfort in not being Dutch or German, other nationalities show the same type of effects. With HiLoDrop any systematic shift up or down by one judge will get smoothed out automatically. To me this seems a great thing for judges, if they are unsure if there was a mistake, they can safely give the benefit of the doubt to the rider knowing that if the other judges saw the mistake then it will be scored correctly.
As Stephen points out some JSP actions would become automatically corrected by this method; for example a judge misses a mistake in a change-line then this will get corrected by HiLoDrop also for the 95% of competitions that have no JSP! But even with a JSP the Eilberg effect showed up, because it is not about single figures, but about the whole test and that is exactly the effect that HiLoDrop will correct.
It is not perfect of course, that Piaffe on the centerline can get an unnecessary correction, but the judge at C score still stands (and this would only really be an effect if neither H or M saw the same good or bad feature). But the vast majority of another anomalies would be corrected. If Stephen wants to treat that Piaffe correctly then we should go for a judging system that builds on those vision differences! E and B judge the side-view, C judges the straightness and sway!
To the best of my knowledge all of the (non-fight-based) judged Olympic sports use some form of High/Low score dropping. Even in Equestrian, Reining uses such corrections. I doubt that Reining judges worse at their jobs than Dressage judges, but their community has recognized that this does a better job for the vast majority of cases
HiLoDrop is better than what we have and it meets the challenge of doing the best we can with the system we have; the opinion of the majority of the judges dominates; no judge’s scores are systematically excluded and their opinion appears in the final score sheet;and the ranking is less sensitive to individual judges. This approach is not intended to be a replacement for an overhaul of the judging system – such as decimal (0.1) marking and/or more explicit codes of points – but it can instantly, without score inflation and without real cost to the sport or the need for any judge retraining, correct for a wide variety of anomalies while aligning the sport with the judging methods used in other Olympic disciplines.
by David Stickland for Eurodressage
Related Links
Sarah Warne: A Grand Prix to Draw a Crowd
FEI Dressage Committee Members Campanella and Lucio Issue Short Statement
Michael Klimke: Shorten the Grand Prix Test, Endanger the Sport
Editorial: Love's Labour's Lost
HiLo Drop