
To paraphrase Dickens, “It was the best of events, it was the worst of events”. August 2017 saw two major senior level dressage events: the European Championships in Gothenburg and the final stage of the CDIO Nations Cup at Hickstead. The first went off largely without hitch and people round the world watched some beautiful dressage, saw a German team dominate the event and with judging that was largely very understandable. The second competition resulted in a deserved win for France, but with a jury of five 5* judges with enormous differences between them in scores and in ranking.
All OK in Gothenburg, Yet Problematic Judging at Hickstead
First the good news, with a jury of five-star judges the results from Gothenburg were very stable. The Team ranking would have been the same without one any of the individual judges being taken into account, or put the other way around, no single judge determined the team ranking. The judges had no doubt who was the winner of the Grand Prix, though the 2nd and 3rd places for Sönke Rothenberger and Cathrine Dufour were very close with only 0.043% between them so inevitably the judges were a little split on that result. The largest difference at the top of the table was for Anna Kasprzak with a 6.1% difference from K to M and a rank difference of 5 to 25. Only 17 of the 62 finishers had judge-to-judge rank differences of less than 10 places, while 10 of the finishers had judge to judge ranking differences of 20 or more places. So, a stable result for the Team medals but a bit less clear for the individual rider scores and ranks.
But what happened at Hickstead? This was the last stage of the 2017 CDIO FEI Nations Cup series. Some of the very top riders were not there, but still there was a respectable number of combinations in the top 100 of the World Dressage Ranking List. Quite a few of the riders brought their younger horses there, but in the Grand Prix 9 out of 29 riders scored above 70% with a total range of scores from 60.266 to 72.434 and more than half of the duos scored more than 69%. As in Gothenburg this was a jury solely of five-star judges, most of whom had judged at Olympic and World Equestrian Games. But things start to look difficult even in the top 3 places with 3rd ranked Katja Gevers placed 1st by the judge at E and 20th by the judge at C with a score difference of 7.5% (ranked 6th ,7th ,6th for the judges at E,H,M). Further down the ranking there was for instance Ulrik Moelgaard who ranked 2nd and 19th. It was the judges at E and B who had this 4.6% and 17-place difference. It was not just a difference of one judge from their colleagues. For example Marie-Emilie Bretenoux had 66.6% from E and 73.0% from M (20th and 5th).
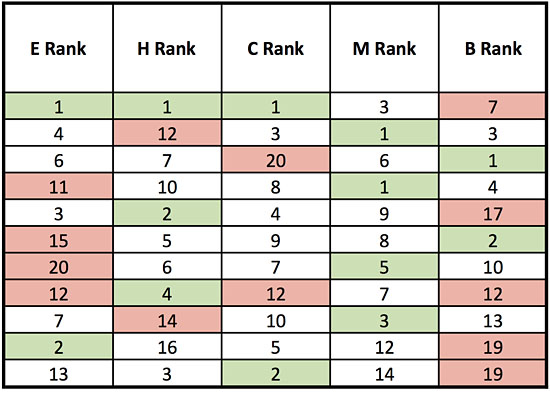
The Grand Prix ranking/positions at the 2017 CDIO Hickstead
“The System Has to Work for All the Developing Riders Too”
 In total 11 out of 28 finishers had judge-to-judge difference of 5% or more and 14 out of 29 had rank differences of 10 or more places. It is often said that there is nothing wrong with the Dressage judging system that better judge education could not ameliorate, and education and support is clearly a vital factor. But this was 5 of the best judges in the world with a combined judging experience that must exceed 100 years. The almost endemic large differences at Hickstead cannot be put down to experience or education. Nor can they be put down to the other regularly used explanation of position. Some of the largest differences in score and rank were between the judges at E and B who have an almost identical view of every movement. We can’t even say that one judge had a “bad day” as 6 out of the possible 10 combinations of judges had differences of 5% or more.
In total 11 out of 28 finishers had judge-to-judge difference of 5% or more and 14 out of 29 had rank differences of 10 or more places. It is often said that there is nothing wrong with the Dressage judging system that better judge education could not ameliorate, and education and support is clearly a vital factor. But this was 5 of the best judges in the world with a combined judging experience that must exceed 100 years. The almost endemic large differences at Hickstead cannot be put down to experience or education. Nor can they be put down to the other regularly used explanation of position. Some of the largest differences in score and rank were between the judges at E and B who have an almost identical view of every movement. We can’t even say that one judge had a “bad day” as 6 out of the possible 10 combinations of judges had differences of 5% or more.
We are left with the conclusion that the scoring system has failed the judges and in turn failed the riders, at least at Hickstead. We can argue that this was “just one event”, but every event is “just one event” and at every event riders want a correct analysis of their performance and countries expect that their riders will be correctly ranked. It is wonderful that riders like Isabel Werth can perform and have unanimous agreement on their ranking and score, but the system has to work for all the developing riders too. The riders at Hickstead were not expecting to score 80+ but they also should not expect 7.5% differences and ranks from 1st to 20th in a 29-rider field. Any statements that this type of problem can be cured by education alone are clearly not supported by these two events, typically for riders at the top the system works satisfactorily, but for those climbing the ladder the system has clearly failed.
Dressage Judges Working Group Proposes Valuable Changes
The FEI Dressage Judges Working Group (DJWG) has recommended prototyping of a Code of Points approach and that work is underway but will clearly take time and has yet to be demonstrated and tested. They have also proposed the HiLo system where final scores are calculated by taking the movement by movement judges scores and taking the average of the middle scores (so 3 out of 5 or 5 out of 7 judges). It is interesting to ask what effect these would have had if they had been applied for these two events.
 At Hickstead there was typically one judge high and one low for each rider so the normal final score and the HiLo are almost the same, the average change was +0.05% with a standard deviation of 0.2%, so no big changes. But the ranking was almost certainly improved. The 3rd - 5th placed rider had scores of 70.90, 70.88 and 70.82 so almost identical, but the 3rd placed rider, Katja Gevers, score was strongly influenced by one judge (B was 7.5% above C and 5.6% above the average of the other 4 judges). HiLo reduces this influence and moves her to 5th place. Here we can note that it also automatically applies the equivalent of 5% rule that can be used in championships with a JSP but is not available for events without a JSP. HiLo also bumps up the 4th (USA) and 5th (FRA) ranked riders to an equal 3rd place at 70.934. Without a very detailed video reanalysis we can’t really know what the theoretical correct ranking should have been, but we can see that the new ranking more represents the majority of the jury and is less influenced by a single judge. HiLo did not change the team ranking even when applied to the whole
At Hickstead there was typically one judge high and one low for each rider so the normal final score and the HiLo are almost the same, the average change was +0.05% with a standard deviation of 0.2%, so no big changes. But the ranking was almost certainly improved. The 3rd - 5th placed rider had scores of 70.90, 70.88 and 70.82 so almost identical, but the 3rd placed rider, Katja Gevers, score was strongly influenced by one judge (B was 7.5% above C and 5.6% above the average of the other 4 judges). HiLo reduces this influence and moves her to 5th place. Here we can note that it also automatically applies the equivalent of 5% rule that can be used in championships with a JSP but is not available for events without a JSP. HiLo also bumps up the 4th (USA) and 5th (FRA) ranked riders to an equal 3rd place at 70.934. Without a very detailed video reanalysis we can’t really know what the theoretical correct ranking should have been, but we can see that the new ranking more represents the majority of the jury and is less influenced by a single judge. HiLo did not change the team ranking even when applied to the whole
In Gothenburg, the HiLo changes are small since the judging was quite consistent. On average scores would have gone up by 0.11% with a standard deviation of 0.12%. Though we must also recall that the JSP corrected some marks as they can do at Championships. In the Grand Prix the final ranking of Sönke Rothenberger and Cathrine Dufour actually switch with HiLo, as noted above they were very close with 78.343 and 78.340% in the official result, and would have ended up with 78.340 and 78.360. There would have been no other rank changes in the top 13 places, and Isabel Werth’s winning score of 83.743 would have become 83.740. In the Grand Prix Special no rank changes in the top 10 places, while Isabel’s score would have gone up from 83.613 to 83.706, Sönke’s score from 82.479 to 82.588. In the Freestyle the winning score would have gone up from 90.892 to 91.050 and Sönke’s would have moved even closer to first place finishing on 90.775. This also of course shows that an argument used against HiLo that the high scores would disappear is also not obvious, At Gothenburg the winning scores would all have gone up a little, not down! While the changes are smaller at Gothenburg than at Hickstead, they do not seem unreasonable. HiLo does no harm and helps achieve the consensus result when judging differences do appear.
Many Olympic judged sports use the equivalent of HiLo, obvious examples being skating, gymnastics, diving, synchronized swimming, as well as the non-Olympic equestrian sport reining. This is a system easily understood by the public and by competitors. The skaters had the good sense to call it “Trimmed Mean” that has a much less aggressive sound than “Drop” and actually describes exactly what is intended. Using a Trimmed Mean instead of an overall mean more reflects the consensus and reduces the influence of any single judge. Performing it movement by movement softens the effect considerably compared to using Trimmed Mean on the final scores, but will still achieve the same thing if one judge does go consistently high or low.
by David Stickland - Global Dressage Analytics
Photos © Astrid Appels
Related Links
Dressage Judging Working Group Makes Recommendations for 2018 Rule Amendments
David Stickland: Moving Towards a Stable Score Future
Wayne Channon: Disaster Waiting to Happen